This is the third part of a series on Docker and Kubernetes networking. We’ll be tackling how Kubernetes’s kube-proxy component uses iptables to direct service traffic to pods randomly. We’ll focus on the ClusterIP type of Kubernetes services.
The goal of this post is to implement the iptables rules needed for a service like:
|
|
The previous posts so far are:
Like the first two articles, we won’t use Docker or Kubernetes in this post. Instead, we’ll learn the underlying tools used.
Recall that Kubernetes creates a network namespace for each pod. We’ll be manually creating network namespaces with python HTTP servers running, which will be treated as our “pods.”
Note: This post only works on Linux. I’m using Ubuntu 19.10, but this should work on other Linux distributions.
Update (March 11, 2021)
- Correct typos from
10.100.100.100.8080to10.100.100.100:8080
create virtual devices and run HTTP servers in network namespaces
We’re going to quickly set up an environment as we did in the previous post.
If a refresher is needed on any of the following, please take a look at How do Kubernetes and Docker create IP Addresses?! and How Docker Publishes Ports.
Let’s get started. Enable IP forwarding by running:
|
|
Now we need to
- create a virtual bridge (named
bridge_home) - create two network namespaces (named
netns_dustinandnetns_leah) - configure
8.8.8.8for DNS in the network namespaces - create two veth pairs connected to
bridge_home - assign
10.0.0.11to the veth running innetns_dustin - assign
10.0.0.21to the veth running innetns_leah - setup default routing in our network namespaces
|
|
Next, create iptables rules to allow traffic in and out of the bridge_home device:
|
|
Then, create another iptables rule to masquerade requests from our network namespaces:
|
|
Moving on, start an HTTP server in the netns_dustin network namespace:
|
|
Finally, open another terminal and start an HTTP server in the netns_leah network namespace:
|
|
At this point, our environment will look like:
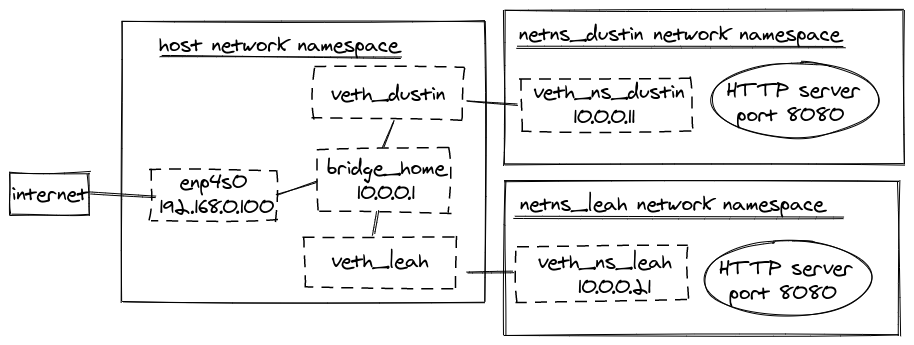
Note: Your IP address may differ from the
192.168.0.100and the interface may have a different name thanenp4s0.
For a sanity check, the following commands should work:
|
|
add a virtual IP in iptables
When a Kubernetes Service is created a ClusterIP is assigned for that new service. Conceptually, a ClusterIP is a virtual IP. kube-proxy in iptables-mode is responsible for creating iptables rules to handle these virtual IP addresses as described in Virtual IPs and service proxies.
Let’s make a simple iptables rule to see what it takes to handle a virtual IP address. Later we’ll refactor to align our rules with how kube-proxy creates rules.
Note: I’m going to assume some familiarity with iptables. Check out How Docker Publishes Ports if you’re not comfortable with the following sections.
Create a new chain named DUSTIN-SERVICES in the nat table by running:
|
|
Next, we’ll want the PREROUTING and OUTPUT chains to look through the
DUSTIN-SERVICES chain via:
|
|
At this point, we can then create a rule in the DUSTIN-SERVICES chain to handle a virtual IP.
Our virtual IP will be 10.100.100.100. Let’s create a rule that directs traffic for
10.100.100.100:8080 to 10.0.0.11:8080. Recall, that 10.0.0.11:8080 is the python HTTP
server running in the netns_dustin namespace.
|
|
This looks very familiar to a rule we created in
How Docker Publishes Ports! This time we’re
specifying a destination of 10.100.100.100 instead of a local address type.
Let’s request our virtual IP by executing:
|
|
Nice! We’ve just handled traffic for a virtual IP!
Now for some bad news. Let’s try requesting the virtual IP address from netns_dustin.
|
|
This command may succeed for some and will fail for others. What gives?!
enable hairpin mode (and promiscuous mode)
If the last command failed for you, I’m going to bet you have Docker running. That was the case
for me at least. So why is Docker interfering? Well, it technically isn’t, but Docker
enables a little setting called net.bridge.bridge-nf-call-iptables. This configures bridges
to consider iptables when handling traffic. This also causes issues with a request leaving
a device that is destined for the same device, which is exactly the scenario we hit in the last
command!
To be super clear, we have a request leaving veth_dustin which has a source IP address of 10.0.0.11.
The request is destined for 10.100.100.100. Our iptables rule then performs a DNAT on
10.100.100.100 to 10.0.0.11. This is where the problem happens. The request needs to be
directed to where the request came from!
Let’s get everyone’s environment configured the same way. This means that if the last command worked for you, we’re going to break it here pretty soon. Fun stuff.
First, check if net.bridge.bridge-nf-call-iptable is enabled.
|
|
If you get the following error:
sysctl: cannot stat /proc/sys/net/bridge/bridge-nf-call-iptables: No such file or directory
then run the following command:
|
|
This will load the br_netfilter module. After run sysctl net.bridge.bridge-nf-call-iptables
again.
I think everyone should be seeing net.bridge.bridge-nf-call-iptables is enabled (1 output).
If for some reason it’s disabled (0) then run the following:
|
|
Now everyone should see the following command fail:
|
|
Now for the fix! We need to enable hairpin mode on veth_dustin connected to bridge_home.
Hairpin mode enables a request leaving a device to be received by the same device.
Fun fact:
veth_dustinis called a port onbridge_home. Similar to having a physical ethernet cable plugged into a port on a physical bridge and the other end is plugged into a physical computer.
To enable hairpin mode on veth_dustin, run:
|
|
Try the following command again:
|
|
It’s a success!
Since we’ll want our network namespaces to be able to talk to themselves via our virtual IPs we’ll need hairpin mode enabled on each port of the bridge device. Fortunately, there’s a way to configure this on the bridge device instead of each port.
Start by undoing what we did earlier and disable hairpin mode:
|
|
Note: This previous step isn’t technically required, but it’ll help to demonstrate the next step works.
Bridges can be in promiscuous mode, which will treat all attached ports (veths in
our case) as if they all had hairpin mode enabled. We can enable promiscuous mode on bridge_home
by running:
|
|
I don’t know why promiscuous is shortened to promisc. I do know I’ve spelled promiscuous wrong so many times while researching. Maybe that’s why?
Run the following beloved command again:
|
|
Success again! With promiscuous mode enabled on bridge_home, we won’t have to worry about
enabling hairpin mode on each veth, such as veth_leah, in the future!
align iptables rules with kube-proxy
So far we’ve created a single iptables rule to handle one service (10.100.100.100) with one backend (10.0.0.11).
We created this rule in a chain named DUSTIN-SERVICES, which is named similarly to kube-proxy’s KUBERNETES-SERVICES.
kube-proxy creates a chain per service and has KUBERNETES-SERVICES jump to the respective service chain based on the
destination.
Let’s start by creating a new chain for our service. We’re going to name our service HTTP. kube-proxy uses hashes in its chain names, but we’ll stick with HTTP to help with understanding. Create a new chain by running:
|
|
Let’s add a rule to our DUSTIN-SVC-HTTP chain that will direct traffic to our backend (10.0.0.11).
|
|
Finally, we’ll want DUSTIN-SERVICES to use the DUSTIN-SVC-HTTP chain. Delete the previous rule we created in DUSTIN-SERVICES via:
|
|
and add a rule in DUSTIN-SERVICES to jump to DUSTIN-SVC-HTTP on matching destination via:
|
|
At this point, the following commands will remain successful:
|
|
In the future, adding a new service consists of:
- create a new chain for the service, such
DUSTIN-SVC-HTTP - create a rule in the service chain to direct traffic to a backend, such as
10.0.0.11 - add a rule to
DUSTIN-SERVICESto jump to the service chain, such asDUSTIN-SVC-HTTP
refactor service chain to support multiple backends
We just refactored our DUSTIN-SERVICES chain to jump to individual service chains. Now, we want to refactor
our service chain (DUSTIN-SVC-HTTP) to jump to other chains for directing traffic to backends.
Note: I’ve been using the word backend here, but these are also referred to as endpoints in Kubernetes. Typically, the endpoints are IP addresses of pods.
Let’s create a new chain for our 10.0.0.11 endpoint. kube-proxy also uses a hash for these chain names, but we’ll create a chain named
DUSTIN-SEP-HTTP1 representing the first service endpoint (SEP) for HTTP. Create the new chain via:
|
|
And we’ll add a familiar-looking rule to the new DUSTIN-SEP-HTTP1 chain:
|
|
We’ll then delete the rule we added to DUSTIN-SVC-HTTP and add a rule in DUSTIN-SVC-HTTP to jump to DUSTIN-SEP-HTTP1.
|
|
The following commands should still work:
|
|
Now we’re ready to start adding additional backends.
use iptables to serve random backends for virtual IPs
As mentioned in the Kubernetes documentation, kube-proxy directs traffic to backends randomly. How does it do that? iptables of course!
iptables support directing traffic to a backend based on probability. This is a super cool concept to me because I previously thought iptables was very deterministic!
Let’s start by adding a new chain and rule for our second HTTP backend (10.0.0.21) running in the netns_leah network namespace.
|
|
We’ll then need to add another rule to the DUSTIN-SVC-HTTP chain to randomly jump to the DUSTIN-SEP-HTTP2 chain we just created. We can
add this rule by running:
|
|
It’s very important to notice that we are inserting this rule to be first in the DUSTIN-SVC-HTTP chain. iptables goes down the list of rules in order.
So by having this rule first, we’ll have a 50% chance of jumping to this chain. If it’s a hit, iptables will jump to DUSTIN-SEP-HTTP2. If it’s a miss, then
iptables will go to the next rule, which will always jump to DUSTIN-SEP-HTTP1.
A common misconception is that each rule should have a probability of 50%, but this will cause problems in the following scenario:
- iptables looks at the first rule (the jump to
DUSTIN-SEP-HTTP2) and let’s say it’s a miss on the 50% - iptables looks at the next rule (the jump to
DUSTIN-SEP-HTTP1) and let’s say it’s also a miss on the 50%
Now our virtual IP wouldn’t direct to any backend! So the probability is based on the number of remaining backends to choose from. If we were to insert a third backend, that rule would have a probability of 33%.
Anyways, if we then run the following command:
|
|
We’ll see requests being made randomly to our python HTTP servers running in netns_leah and netns_dustin network namespaces. This is load balancing via iptables!
closing thoughts
After these three posts on container and pod networking, I’ve learned more about networking than I ever thought I would. The remaining topics I’d like to learn are:
- how does kube-proxy work in IPVS mode? Update: I dove into this on IPVS: How Kubernetes Services Direct Traffic to Pods
- conntrack and how it’s used in iptables rules by kube-proxy
- how are virtual tunnels and BGP optionally used in multi-node Kubernetes clusters?
- I talk about using BGP and BIRD to do this in Kubernetes Networking from Scratch: Using BGP and BIRD to Advertise Pod Routes.
Have any knowledge to share about the above topics? Or any other additional questions? Then please feel free to reach out and let me know on LinkedIn, or GitHub.